HTML 5 no tiene directamente nada que nos proporcione facilidades de acceso a archivos en el ordenador del usuario; pero el W3C define un API estándar para solventar, al menos en parte, esa carencia. Se trata del File API.
Su propio nombre es algo engañoso, podríamos esperarnos un completo API para lectura y escritura de archivos desde y hacia un disco duro en nuestro explorador de Internet. Sin embargo, dista bastante de ello, al menos hasta el presente.

El File API nos proporciona rutinas JavaScript para poder recabar archivos de nuestro disco duro y manipularlo parcialmente -abrirlo y explorar sus datos, exclusivamente-. Lo verdaderamente atractivo es que permite hacerlo directamente desde el disco duro local y el explorador, sin necesidad de ningún tipo de transacción de datos a través de Internet.
Notorio también es saber lo que no hace, fundamentalmente, no es capaz de modificar contenidos ni de crear archivos nuevos. Así que para almacenar información nueva, hemos de volver nuestra vista a otras opciones, que pueden pasar por el Web Storage, en unos casos, o el uso de soluciones del lado del servidor en otros.
Las bases oficiales de la definición del estándar File API (en inglés) se pueden consultar en:
¿Cómo se implementa?
Algunas consideraciones:- No se trata de un sistema general de lectura de archivos, hemos de prever con qué tipo de archivos vamos a trabajar.
- Las posibilidades tampoco son amplias, pero sí las más interesantes: archivos de texto y archivos de imágenes.
- Tendremos de comprobar que el navegador de Internet nos da el soporte necesario para trabajar con el File API.
| IE | Firefox | Chrome | Safari | Opera | Safari iOS | Android |
| 10 | 3.6 | 8 | 6 | 11.1 | - | 3 |
Para determinar si un explorador -en una versión instalada- da soporte al File API, bastará con hacer una llamada al método FileReader, si éste no está definido es que no tendremos soporte, la rutina de comprobación es tan simple como lo que sigue:
Listado 1a: Rutina de comprobación del soporte para File API.
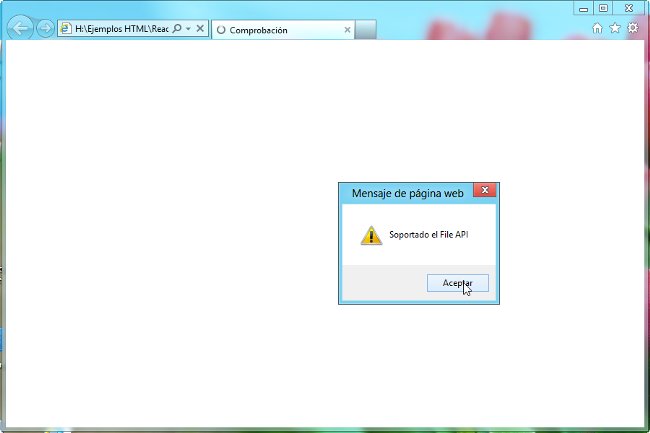
if (typeof window.FileReader!=="undefined")
{
// Soportado el File API
}
else
{
// No es soportado el File API
}
Listado 1b: Ejemplo completo de implementación en HTML 5 de la rutina de comprobación del soporte para File API. Una ventana emergente nos informará de ello.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" lang="es-es">
<title>Comprobación</title>
<script>
if (typeof window.FileReader!=="undefined")
{
alert("Soportado el File API");
}
else
{
alert("No es soportado el File API");
}
</script>
</head>
<body>
<h3>Comprobación del soporte para File API</h3>
</body>
</html>
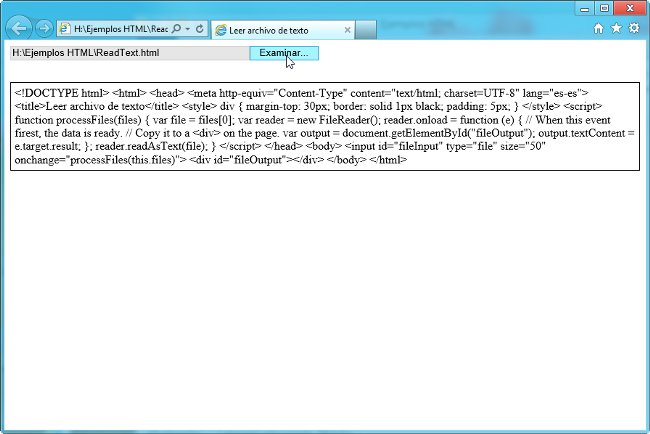
Lectura de archivos de texto
Realmente debería decirse "lectura de un archivo cómo texto", desde el momento en que no hay ningún tipo de comprobación de que así lo sea y puede mostrarse como tal cualquier archivo, sea o no de texto.En el Listado 2 se recoge un ejemplo sencillo, sin comprobaciones de compatibilidad ni adornos de ninguna clase, pero plenamente funcional. Seguidamente explicaremos lo esencial del código:
- El núcleo del proceso se programa en la función processFiles que recibe como parámetro una matriz de cadenas de nombres de archivos.
- Dentro de la función, lo primero que hacemos es declarar una variable que contiene el valor de la primera cadena de nombre de archivo, dado que trabajaremos con un único archivo -el primero pasado, normalmente también el único-.
- Para la lectura de los datos se utiliza el método de lectura como caracteres de texto desde una dirección URL -reader.readAsText(file)-
- Para su exposición, algo tan simple como rellenar el área con los caracteres recién leídos -output.textContent = e.target.result;-
- En el cuerpo de la página se crea un formulario, con un elemento input, de tipo file; esto es, que desplegará un área de entrada de texto y un botón de comando para la navegación y localización de archivos, en su caso.
- Cuando el botón sea pulsado con un nombre de archivo válido escrito en el área de texto o seleccionado en la caja de diálogo abierta, se llamará a la función anteriormente comentada processFiles.
- Respecto al apartado de estilo -style-, nada especial que comentar, se fija un mínimo de características del área en que se mostrará el texto.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" lang="es-es">
<title>Leer archivo de texto</title>
<style>
div {
margin-top: 30px;
border: solid 1px black;
padding: 5px;
}
</style>
<script>
function processFiles(files) {
var file = files[0];
var reader = new FileReader();
reader.onload = function (e) {
// Cuando éste evento se dispara, los datos están ya disponibles.
// Se trata de copiarlos a una área <div> en la página.
var output = document.getElementById("fileOutput");
output.textContent = e.target.result;
};
reader.readAsText(file);
}
</script>
</head>
<body>
<input id="fileInput" type="file" size="50" onchange="processFiles(this.files)">
<div id="fileOutput"></div>
</body>
</html>
Lectura de archivos de imágenes
Realmente debería decirse -lectura de un archivo cómo datos y se exponen como fondo del documento o área del documento-. Concretamente, lee los datos binarios y los expone, tampoco, como en el caso de la lectura como texto, hay ninguna comprobación de tipo -de su adecuación-.Los tipos de archivos correctamente interpretados, hasta el presente, son JPEG, PNG, GIF y TIFF, aunque no hay una especificación clara al respecto.
En el Listado 3 se recoge un ejemplo sencillo, sin comprobaciones de compatibilidad ni adornos de ninguna clase, pero plenamente funcional. Seguidamente explicaremos lo esencial del código:
- Lo esencial de la función processFiles permanece invariable.
- Asimismo lo es el formulario de llamada y búsqueda o entrada del nombre de archivo en el cuerpo del documento HTML.
- Para la lectura de los datos se utiliza el método de lectura de datos en bruto desde una dirección URL -reader.readAsDataURL(file);-
- Para su exposición, algo tan simple como rellenar el fondo del área con una imagen con los datos recién leídos -fileOutput.style.backgroundImage = "url('" + e.target.result + "')";-
- Respecto al apartado de estilo -style-, aquí sí tiene una importancia sustancialmente mayor. Se fijan las dimensiones del área en que se mostrará la imagen, que ésta sea del 100%, sin repetición y alineada al centro del área:
width: 300px;
height: 300px;
background-size: 100%;
background-repeat: no-repeat;
text-align: center;
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" lang="es-es">
<title>Leer archivo de imagen</title>
<style>
div {
margin-top: 30px;
border: solid 1px black;
padding: 5px;
width: 300px;
height: 300px;
background: lightyellow;
background-size: 100%;
background-repeat: no-repeat;
text-align: center;
}
</style>
<script>
function processFiles(files) {
var file = files[0];
var reader = new FileReader();
reader.onload = function (e) {
// Cuando éste evento se dispara, los datos están ya disponibles.
// Se trata de copiarlos a una área <div> en la página.
var output = document.getElementById("fileOutput");
fileOutput.style.backgroundImage = "url('" + e.target.result + "')";
};
reader.readAsDataURL(file);
}
</script>
</head>
<body>
<input id="fileInput" type="file" size="50" onchange="processFiles(this.files)">
<div id="fileOutput"></div>
</body>
</html>
Jaime Peña Tresancos
Escritor. Colaborador habitual de revistas de tecnología y experto en nuevas tec...