Cómo generar el código HTML a partir de un contenido editado por el usuario, usando el framework de creación de editores de texto enriquecido Prosemirror. Usaremos la clase DOMSerializer de Prosemirror y algunas funciones nativas de Javascript.

Vamos a continuar el Manual de creación de editores de texto enriquecidos para la web con las explicaciones necesarias para desempeñar una de las tareas clave, que nos plantearemos tarde o temprano al desarrollar nuestro propio editor. Esta tarea consiste en obtener el código HTML correspondiente al contenido que el usuario está escribiendo en el área editable. No es algo complejo, pero sí tiene algunos detalles que merece la pena comentar con calma y de paso ver algunos ejemplos nuevos.
Clase DOMSerializer
Como hemos señalado en repetidas ocasiones, ProseMirror no trabaja con etiquetas HTML directamente cuando estamos creando contenido en el área del editor. En cambio, ProseMirror usa su propio modelo de datos para crear una jerarquía de objetos que representa al documento. Es algo parecido al DOM del navegador, aunque tampoco es exactamente lo mismo.
Así pues, para realizar la tarea de extraer el código HTML de un editor necesitaremos realizar unos pasos encaminados a obtener la traducción a HTML del contenido editable. Es decir, pasar de la estructura de objetos propia de ProseMirror para modelizar un documento a la estructura de árbol de etiquetas HTML. Para ello usaremos la clase DOMSerializer.
En la documentación de ProseMirror te explican cómo usar el constructor para obtener tu instancia de DOMSerializer, pero existe una manera más cómoda para trabajar, que es generarlo a partir del schema que hemos usado para crear el estado inicial del editor.
Para ello usamos el método estático fromSchema() de la clase DOMSerializer, enviando como parámetro el schema de nuestro editor.
DOMSerializer.fromSchema(schema)
Una vez tenemos una instancia de DOMSerializer podemos obtener la representación en el DOM del contenido de nuestro editor, mediante la invocación del método serializeFragment().
Estos pasos los conseguimos, todos de una, con esta línea de código.
let fragment = DOMSerializer.fromSchema(schema).serializeFragment(view.state.doc.content);
No obstante, aunque pudiéramos pensar que esa variable fragment contiene ahora el HTML que queremos obtener, no es exactamente así.
Qué es un DocumentFragment
DocumentFragment es un objeto nativo del navegador que representa una jerarquía de objetos de documento HTML que no tiene padre. Es como un pedazo de DOM, pero que no está insertado en ningún lugar de la página.
El objeto documentFragment, al ser un pedazo de DOM, responde a muchas de las características y utilidades que el propio DOM de la página. Lo podemos usar, por ejemplo, para vincularlo a un área del documento, inyectando ese fragmento como hijo de una etiqueta del documento.
document.body.appendChild(fragment);
Cómo serializar un Documento para volcar su contenido en un área de la página
Con lo que hemos aprendido hasta aquí seríamos capaces de acceder al editor, extraer el fragmento de DOM que componga el contenido que el usuario haya escrito y finalmente volcarlo para que se vea en algún lugar de la página.
Eso es justamente lo que vamos a ver en el siguiente código. Comenzamos mostrando un un botón en la página y una división que está vacía.
<button id="serializar">Serializar a HTML</button>
<div id="salida"></div>
Y ahora vamos a crear un manejador de evento para que, al pulsar el botón, se envíe el documento actual del editor a la división que hemos colocado inicialmente vacía.
document.getElementById('serializar').addEventListener('click', function() {
let fragment = DOMSerializer.fromSchema(schema).serializeFragment(view.state.doc.content);
document.getElementById('salida').appendChild(fragment);
})
Cómo obtener una cadena con el código HTML del documento del editor
El ejemplo anterior está muy bien, pero habrás pensado que la mayor parte de las veces no necesitas volcar ese fragmento en otro elemento de la página, sino obtener su código fuente, la cadena del HTML, para luego enviarlo a un backend que lo va a procesar.
Esto lo podemos conseguir muy fácil con dos funciones de ejemplo, que reciben un fragmento y devuelven un código HTML.
function getHtmlCodeFromFragment(fragment) {
const serializer = new XMLSerializer();
return serializer.serializeToString(fragment);
}
Esta primera función hace uso de una clase disponible en el navegador llamada XMLSerializer. Primero creamos un objeto de serialización y luego hacemos que convierta en string un fragmento dado por parámetro.
El problema de esta clase es que la serialización la produce en XML y le inserta algunas etiquetas y atributos de más al código HTML para hacerlo tan formal como el XML es. El resultado que obtenemos es como el que podemos ver en esta imagen.
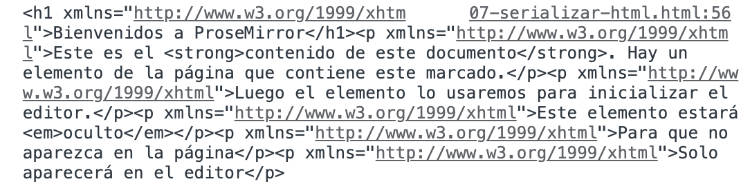
Si bien es cierto que podrías montarte un tratamiento con expresiones regulares para eliminar las partes que no te interesan, resulta complejo y más pasos adicionales que realizar, por lo que preferimos esta otra función.
function getHtmlCodeFromFragmentFromDom(fragment) {
const auxiliarElement = document.createElement('div');
auxiliarElement.appendChild(fragment);
return auxiliarElement.innerHTML;
}
En esta segunda alternativa de conversión nos valemos de un elemento auxiliar, creado al vuelo con Javascript. Ese elemento simplemente está en la memoria de Javascript, no lo hemos colocado en ningún lugar de la página y sobre él, le inyectamos el fragmento.
Posteriormente devolvemos la propiedad innerHTML del elemento auxiliar, con lo que obtenemos el HTML limpio para hacer con él lo que necesitemos.
Conclusión
En este artículo hemos aprendido a realizar un paso fundamental al trabajar con editores de texto enriquecido, que es la generación de código HTML en una cadena de texto que luego podamos utilizar para el objetivo final de nuestro editor.
En un siguiente artículo vamos a ver cómo podríamos generar Markdown en lugar de HTML, ya que trabajar con código en Markdown tiene todavía más ventajas que hacerlo con HTML, por ejemplo la seguridad de que no se usarán etiquetas más allá de las permitidas en el markdown.
Miguel Angel Alvarez
Fundador de DesarrolloWeb.com y la plataforma de formación online EscuelaIT. Com...