Cómo inicializar el contenido del editor de texto que estamos creando con Prosemirror, usando la clase DOMParser que nos permite construir un documento a partir del HTML contenido en un elemento de la página.

En el artículo anterior aprendimos acerca de los comandos en ProseMirror. Vimos que mediante estos comandos éramos capaces de aplicar alguna funcionalidad al editor, aunque todavía ha sido todo bastante básico.
En este artículo vamos a abordar otro tema básico como es la inicialización del editor con un contenido determinado, que vamos a extraer de otro elemento de la página.
El contenido del documento editable con Prosemirror
Una de las características de ProseMirror es que el editor de texto no tiene exactamente HTML como contenido. En cambio, lo que tiene es una jerarquía de objetos cuyas propiedades definirán el contenido editado por el usuario. Esto ofrece diversas ventajas, como la posibilidad de no generar HTML basura, evitar que el código se poluya con etiquetas que no queremos y facilita otros factores como la colaboración en tiempo real.
Puedes pensar en el contenido del documento como una especie de DOM, similar al que mantiene el navegador para la creación de un documento HTML. Por ejemplo, si tenemos un editor que representa un par de párrafos lo que tendremos será un nodo "doc", del que cuelgan dos nodos "paragraph", donde cada uno de ellos contendrá un nodo de texto.
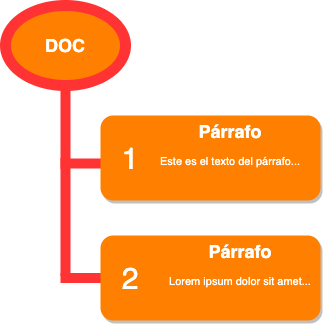
El contenido del documento editable lo encontramos en la propiedad doc del estado del documento. Es una estructura de datos de solo lectura con la jerarquía de objetos que forman parte de un documento.
Inicializar el estado del documento
A la hora de crear el documento, hasta ahora no entregábamos ninguna inicialización en particular. Simplemente llamábamos al método EditorState.create() al que le pasábamos el schema de este documento y, opcionalmente, vimos que también le podíamos entregar un conjunto de plugins.
let state = EditorState.create({
schema,
});
Esta inicialización la podemos mejorar por medio de una propiedad llamada "doc" donde podremos colocar el valor del documento que queremos inicializar.
let state = EditorState.create({
schema,
doc: jearquia_nodos_prosemirror
});
Sin embargo, para inicializarlo necesitaremos una jerarquía de nodos de ProseMirror, que no vamos a crear a mano, sino que vamos a obtener a través de un elemento de la página web.
Clase DOMParser
Para la creación de un objeto documento propio de ProseMirror a partir de un objeto del DOM de la página vamos a usar la clase DOMParser.
Esta clase pertenece al package prosemirror-model, que si no hemos instalado todavía lo tendremos que instalar en el proyecto con npm.
npm i prosemirror-model
Una vez instalada en el proyecto podemos usarla en un módulo de Javascript, realizando el correspondiente import.
import { DOMParser } from "prosemirror-model"
Ahora, para conseguir el objeto del documento necesitamos realizar un paso que está compuesto de dos "sub-pasos".
- Primero necesitamos indicar a
DOMParsercuál es el esquema que queremos usar, ya que este esquema es necesario para extraer correctamente los nodos que verdaderamente vamos a querer, a partir del objeto del DOM. - Parsear el elemento del DOM que queramos.
Este proceso se resume en este código:
DOMParser.fromSchema(schema).parse(content)
Siendo la variable schema el esquema que hemos usado siempre hasta ahora y content un objeto del DOM desde el que vamos a extraer el contenido.
Cómo obtener un elemento del DOM
Ahora vamos a ver cómo obtener un elemento del DOM de la página, aunque esto es algo de Javascript básico que seguramente ya sepas.
Tendremos un poco de HTML, en un elemento cualquiera que haya en la página:
<div id="content">
<h1>Bienvenidos a ProseMirror</h1>
<p>Este es el <b>contenido de este documento</b>. Hay un elemento de la página que contiene este marcado.</p>
<p>Luego el elemento lo usaremos para inicializar el editor.</p>
<ul>
<li>Este elemento estará <i>oculto</i></li>
<li>Para que no aparezca en la página</li>
<li>Solo aparecerá en el editor</li>
</ul>
</div>
Accedemos al elemento a través de su identificador, atributo id:
let content = document.getElementById('content');
El elemento lo queremos ocultar
Solo un detalle más sobre este elemento del DOM. En realidad solo lo queremos para inicializar el contenido del documento del editor, pero no queremos que se muestre como contenido en la página, por ello es común que quieras poner un poco de CSS simplemente para ocultar el documento.
#content {
display: none;
}
Script completo de inicialización del editor
Veamos aquí completo el script de inicialización de este ejemplo de ProseMirror:
import { schema } from "prosemirror-schema-basic";
import { EditorState } from "prosemirror-state";
import { EditorView } from "prosemirror-view";
import { keymap } from "prosemirror-keymap";
import { DOMParser } from "prosemirror-model"
import {
baseKeymap,
} from "prosemirror-commands";
let content = document.getElementById('content');
let state = EditorState.create({
plugins: [
keymap(baseKeymap),
],
doc: DOMParser.fromSchema(schema).parse(content)
});
let view = new EditorView(document.getElementById('editor'), {
state,
});
Conclusión
Si te fijas, una vez puesto en marcha el ejercicio, encontrarás que no todas las etiquetas del DOM se han inicializado, de hecho solamente se han inicializado el encabezamiento y los párrafos, así como las etiquetas <b> y <i>. Los elementos de la lista al mostrarse en el editor aparecen como párrafos normales.
Esto es debido al schema que estamos utilizando en este ejercicio, que no permite elementos de listas. Como dijimos anteriormente es un esquema básico, que podemos comprobar está bastante limitado No te preocupes porque lo podemos personalizar para mejorar la cantidad de tipos de objetos permitidos, como veremos más adelante.
Miguel Angel Alvarez
Fundador de DesarrolloWeb.com y la plataforma de formación online EscuelaIT. Com...